OpenAI released GPT-5.5 on April 23, 2026. The company is pitching it as "a new class of intelligence for real work", with the biggest gains in agentic coding, computer use, knowledge work, and early scientific research. This post walks through what actually shipped: the variants, pricing against recent competitors, the benchmark numbers OpenAI published, the safety posture in the system card, and a section on one thing the model still hasn't fixed.
GPT-5.5 comes in two variants:
- gpt-5.5: the base model for Plus, Pro, Business, and Enterprise tiers in ChatGPT and Codex.
- gpt-5.5-pro: a higher-accuracy variant that uses parallel test-time compute on top of the same underlying model. Available to Pro, Business, and Enterprise users in ChatGPT.
In Codex, GPT-5.5 ships with a 400K context window and a separate Fast mode that generates tokens 1.5x faster for 2.5x the cost. In the API, both variants will run with a 1M context window.
OpenAI's headline efficiency claim: GPT-5.5 matches GPT-5.4 per-token latency in production while "using significantly fewer tokens to complete the same Codex tasks". On Artificial Analysis's Coding Index, OpenAI claims GPT-5.5 delivers state-of-the-art intelligence at half the cost of competitive frontier coding models.
GPT-5.5 is priced 2x GPT-5.4 on input and output. For Pro variants, the gap is wider. Below is a verified comparison across the current OpenAI and Anthropic frontier tiers. All figures are per 1M tokens.
A few things worth noting:
- GPT-5.5 base output is $5 more per 1M tokens than Claude Opus 4.7. Input is identical at $5.
- GPT-5.5 Pro is roughly 7x the output cost of Claude Opus 4.7. The Pro variant is positioned for "higher-accuracy" work, not general-purpose prompting.
- Batch and Flex pricing run at half the standard API rate. Priority processing is 2.5x standard. This is unchanged from prior GPT-5.x tiers.
- OpenAI explicitly acknowledges the price hike: "GPT-5.5 is priced higher than GPT-5.4, but is both more intelligent and much more token efficient". The Codex experience is tuned so most users get better results with fewer tokens.
OpenAI published a large benchmark sweep against GPT-5.4, GPT-5.4 Pro, Claude Opus 4.7, and Gemini 3.1 Pro. The numbers below are from OpenAI's launch post, which means they carry OpenAI's own methodology; treat them as self-reported.
Key takeaways:
- Terminal-Bench 2.0 is the cleanest coding-agent win. GPT-5.5 clears GPT-5.4 by 7.6 points and Claude Opus 4.7 by 13.3 points.
- SWE-Bench Pro is the one exception. Claude Opus 4.7 still leads at 64.3% vs GPT-5.5's 58.6%.
- OSWorld-Verified (computer use) has GPT-5.5 ahead of Opus 4.7 by less than a point (78.7% vs 78.0%).
- GDPval wins-or-ties rate at 84.9% is a 17.6-point gap over Gemini 3.1 Pro.
GPT-5.5 clears all competitors on FrontierMath Tier 4, the hardest tier. On Humanity's Last Exam without tools, Claude Opus 4.7 is still ahead. Gemini 3.1 Pro narrowly leads on GPQA Diamond and BrowseComp.
OpenAI singles out scientific research as an area where the model is "strong enough to meaningfully accelerate progress at the frontiers of biomedical research". A concrete data point from the launch post: GPT-5.5 produced a new proof about off-diagonal Ramsey numbers, later verified in Lean.
The feature narrative around GPT-5.5 is less about single-shot code generation and more about sustained work. Early testers described the model as able to:
- Hold context across large systems and carry changes through the surrounding codebase instead of patching one file.
- Reason through ambiguous failures and check assumptions with tools rather than guessing.
- Catch issues in advance and predict testing and review needs without being asked.
The infrastructure detail is where this gets more interesting: OpenAI says Codex itself, running GPT-5.5, wrote load balancing and partitioning heuristics for OpenAI's own serving stack. Those heuristics increased token generation speeds by over 20%. The model is now helping to improve the infrastructure that serves it.
Here's the thing GPT-5.5 has not fixed. Ask it to generate a UI from a plain-language prompt, and it still reaches for the same shape it always has: a grid of rounded cards, each with an image, a heading, a short description, and a price or CTA. Safe, legible, generic.
Below is a UI generated with GPT-5.5 from a short bakery-storefront prompt. Same pattern as every other model in this class:
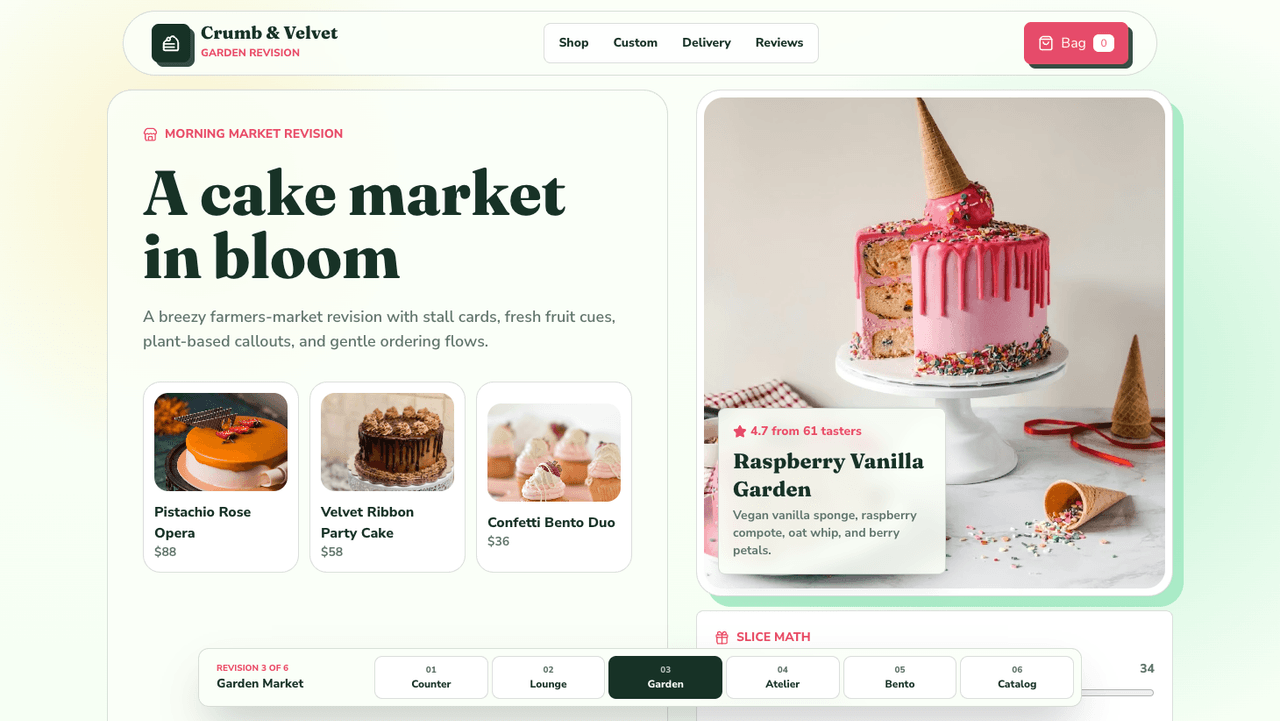
The benchmarks above suggest the model has become meaningfully better at reasoning about code, carrying context across files, and running agentic workflows. It has not clearly moved on visual design. The defaults are still "cards on a soft background with generous padding".
If you want something more opinionated (a proper storefront with counter rush, seasonal cues, a bento shop layout) you still have to prompt for it explicitly, and even then the fallback is a card grid. For UI-first work, Claude Opus 4.7 is still the stronger model. It produces layouts with clearer hierarchy, tighter typography, and fewer reflexive card grids out of the box.
This matters for anyone using Codex or ChatGPT to ship a UI from scratch. A model that is 82.7% on Terminal-Bench 2.0 but still generates the same card layout for a bakery, a SaaS dashboard, and a news site will save you time in the engine room and cost you time in the design review.
The GPT-5.5 system card covers the full preparedness, safety, and alignment evaluation. OpenAI's Preparedness Framework rates models in three high-risk domains (Bio/Chem, Cybersecurity, AI Self-Improvement) against two thresholds: High (capable enough that additional safeguards are required) and Critical (capable enough to cause severe harm without mitigation). GPT-5.5's ratings:
- Biological and Chemical: High. Same as GPT-5.4. The model is capable enough in this domain that OpenAI keeps its bio/chem-specific safeguards active (monitoring, access controls, and refusals on sensitive uplift requests). Not at the Critical threshold.
- Cybersecurity: High, below Critical. An increase over GPT-5.4. OpenAI has tightened cyber safeguards for this launch. The system card states GPT-5.5 does not have the capability to develop "functional zero-day exploits of all severity levels in many hardened real world critical systems without human intervention", which is the Critical threshold.
- AI Self-Improvement: below High. Final-checkpoint evaluations found no plausible chance of reaching the High threshold.
- OpenAI collected feedback from nearly 200 trusted early-access partners before release.
- This is described as OpenAI's "strongest set of safeguards to date".
For cybersecurity work specifically, OpenAI is offering expanded cyber-permissive access to verified Codex users who meet cyber safety criteria, with tighter controls around the highest-risk workflows.
The capability bar has moved.
- 82.7% on Terminal-Bench 2.0.
- 1M token API context window.
- GPT-5.4 per-token latency in production.
Together, those describe a model you can leave alone on a multi-step task and expect to come back to progress. That was not true of GPT-5 at launch, and was shakily true of GPT-5.4. With GPT-5.5 it is the main selling point.
If you are running GPT-5.5 in Codex or ChatGPT and want it to act on your backend rather than just describe changes, the Appwrite API MCP server exposes your project (databases, auth, storage, functions, messaging) as tools the model can call directly. The model reads the live tool schema, calls the API, and your project updates in real time.
The full setup walkthrough lives in the Appwrite Codex guide. A short version is below.
Appwrite ships two MCP servers that both work with Codex:
- Appwrite API MCP: lets the model act on your Appwrite project (create users, list databases, upload files, run functions, etc.).
- Appwrite Docs MCP: lets the model look up current Appwrite documentation instead of relying on what it was trained on.
No credentials required:
codex mcp add appwrite-docs --url https://mcp-for-docs.appwrite.io
codex mcp add appwrite-api \
--env APPWRITE_PROJECT_ID=your-project-id \
--env APPWRITE_API_KEY=your-api-key \
--env APPWRITE_ENDPOINT=https://<REGION>.cloud.appwrite.io/v1 \
-- uvx mcp-server-appwrite
Replace your-project-id, your-api-key, and <REGION> (e.g. fra, nyc, syd) with your own values.
Once connected, a prompt like "create a new user in my Appwrite project with the email demo@example.com" will route through the API MCP and run against your project directly, no code generation in between.